Every sharded-data system (a distributed datastore) has (or aims for) three fundamental properties: data consistency, data availability, and that it is tolerant to a network partition (a subset of nodes not being able to reach the rest of the cluster). But due to simple laws of physics it is impossible to have all of these. With this in mind, we need a way to describe the limitations and tradeoffs that a system chooses to have and the way we can do that is with well-known CAP theorem.
CAP Theorem
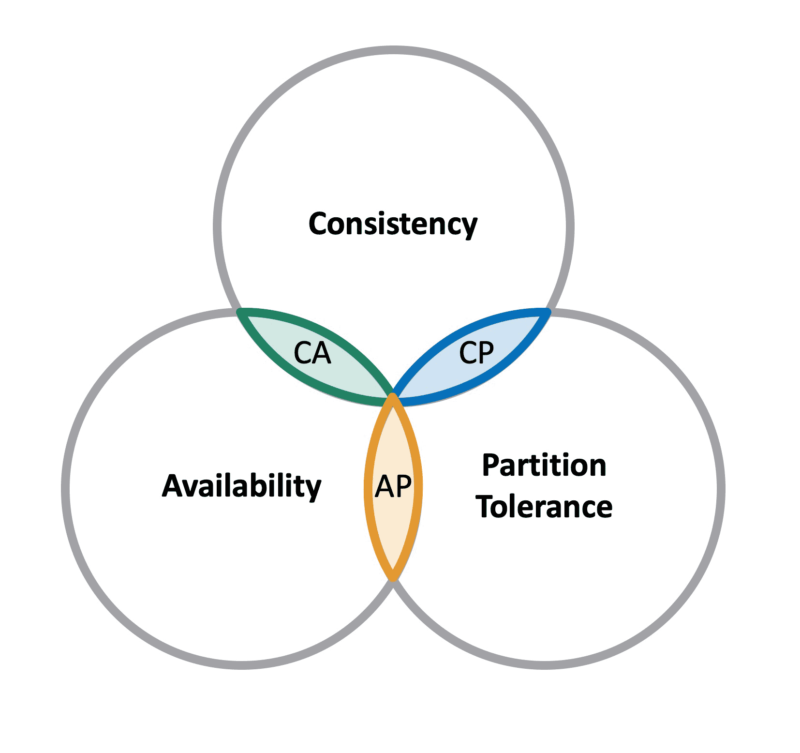
CAP theorem, coined by Eric Brewer (exactly the reason why it is also known as Brewer’s theorem) in the year 2000, in its initial statements tells us that a distributed database out of the three desired properties we mentioned earlier, consistency, availability, and partition-tolerance, can only choose two of those. It is impossible to have all three of them.
The theorem was proved in 2002 by Seth Gilbert and Nancy Lynch and in their paper, the three properties are described as:
- Consistency: any read operation that begins after a write operation completes must return that value, or the result of a later write operation
- Availability: every request received by a non-failing node in the system must result in a response
- Partition tolerant: the network will be allowed to lose arbitrarily many messages sent from one node to another
It is worth noting that consistency described by Gilbert and Lynch is a linearizable consistency, which is one of the strongest consistency models that basically states that when you read some data, you will always get the latest version of it. The client sees the system as it interacts with a single node rather than a cluster of machines. Also to note here is that consistency in CAP is different than consistency in ACID transactions. C in ACID relates to a state of a database in general and C in CAP (or distributed systems in general) is about a single data item in a database.
CP, AP and CA Systems
When describing distributed systems with the CAP theorem we can basically have three categories:
- CP system: consistent and partition-tolerant, but not highly available
- AP system: highly available and partition-tolerant, but not consistent
- CA system: consistent and highly available, but not partition-tolerant
CAP is for Failures
When we talk about CA systems, we can wonder are these really possible to have in the first place? Like we already said, CA systems are systems that choose to be consistent and highly available, but not partition-tolerant, but if you think about it, how can you choose not to have a network partition? Is that even possible? In a geographically distributed system (across regions) you will definitely have network partition, but even if we argue that within a single data center (or even a single rack in a data center) partitions are not possible, that still is not true. To put it simply, we can not avoid a network partition, they will happen sooner or later. Also, a network partition is not only being 100% cut off from the rest of the cluster, if the network is slow and our request simply timeout (they will arrive, but only after our timeout threshold), that is also a network partition.
Because of this, Eric Brewer revised the statement (CAP twelve years later: How the “rules” have changed, 2012) to have the partition tolerance part clearer, so with that, we have a final CAP statement that says that: a distributed datastore can choose only availability or consistency in the presence of a network partition.
What this means is that CAP basically allows us to describe consistency/availability tradeoff only when there is a failure, a partition, but what about a system in a normal operational mode?
Consistency and Latency Tradeoff
In a normal operation mode, the truth is that a system can be available and consistent at the same time. And in the modern-day (cloud) infrastructure, having a partition, especially when a system is operating in a single region, or, even better, in a single DC, is really rare. But despite this, many systems choose not to be (fully) consistent, because having a strong consistency has a cost, and that cost is latency (because of synchronization mechanisms needed to make all the nodes see the latest writes). For example in a single-leader replication, if we have synchronous replication, we choose to be consistent but the latencies are higher. But if we choose the asynchronous replication, we will be less consistent, but our latencies will be much lower.
This means that fundamentally we have a tradeoff between consistency, availability, and latency. Furthermore, when you have a high enough latency that basically means that we are unavailable because the latency will make requests timeout and when they timeout it is basically like having a partition. With all of this in mind, we can say that fundamentally the tradeoff is between consistency and latency.
PACELC
This consistency and latency tradeoff in a normal operation mode was observed and formalized by Daniel Abady in 2012 which lead to his PACELC theorem. PACELC is something like an extension to CAP which allows us to describe a system not just in the case of a partition, but also in its normal operation.
The theorem states:
“In the case of a network partition (P), the system has to choose between availability (A) and consistency (C) but else (E), when the system operates normally in the absence of network partitions, the system has to choose between latency (L) and consistency (C).”
The first part (PAC) is basically the CAP theorem, describing the tradeoff when there is a partition (consistency or availability) and the second part (ELC) describes the tradeoff when we don’t have a partition (consistency or latency).
PACELC Categories
PACELC theorem in general leads to four categories of systems:
- PC/EC: when there is a partition, the system chooses consistency over availability, and in normal operation, it chooses consistency over latency
- PA/EL: when there is a partition, the system chooses availability over consistency, and in normal operation, it chooses latency over consistency
- PC/EL: when there is a partition, the system chooses consistency over availability, and in a normal operation it chooses latency over consistency
- PA/EC: when there is a partition, the system chooses availability over consistency, and in a normal operation it chooses consistency over latency
Here are some examples of real datastores described by PACELC:
| PC/EC | PA/EL | PC/EL | PA/EC |
|---|---|---|---|
| MySQL (async replication) | MySQL (semi-sync replication) | ||
| Zookeeper | |||
| Cassandra | Cassandra | ||
| Kafka | Kafka | ||
| Hazelcast | |||
| IMDGO |
As you can see, almost all databases provide various config options to make it more available or more consistent depending on the user’s need. Zookeeper is strictly PC/EC because Zookeeper is used mainly for cluster coordination so consistency is the top priority. Hazelcast is analyzed in depth by Daniel Abady, check it out here. Regarding IMDGO (In-Memory Data Grid in Go), which you probably didn’t hear of, is a brand new in-memory KV storage (like Hazelcast) written by, well, myself, so I had to put it here 🙂
For PC/EL systems, in practice, they don’t make much sense, because what is the point to strive for low latency/high availability all the time, but when a partition occurs you grind to a halt? But theoretically, they are possible and considered by PACELC.
It is also really important to note is that, unlike partition tolerance, which is a binary state (you have a partition or you don’t), consistency and latency range from low to high, for example, we have various levels of consistency, from the least strong like Read your writes to linearizability which is the strongest one (check this for consistency models refresher).
Summary
Making distributed systems is hard and physics prevents us from having a system that works as if it is like a single node (fast and consistent). We, depending on a particular problem that we target, need to make certain tradeoffs regarding the level of consistency we want. CAP theorem, and later PACELC theorem, helps us to describe the system in this regard thus helping us choose the one that is best for our use case. As soon as we come to a phase where our data has to be sharded and available in multiple locations it becomes important to understand what our backing datastore allows us to have and make future (and present) decisions based on that understanding. It is not good to expect and assume that our data will be, for example, strongly consistent when our database is actually designed for high availability first in mind.